CoRGII: Contextual Tokenization for Graph Inverted Indices
Overview
CoRGII bridges the gap between neural and classical retrieval by combining the semantic fidelity of graph embeddings with the efficiency of inverted indices. It converts continuous graph features into discrete, indexable tokens and uses learned impact weighting and multi-probing to balance accuracy and efficiency.
Motivation
Traditional subgraph retrieval is computationally expensive: exact isomorphism is NP-hard, and even approximate neural matchers require comparing every corpus graph. In contrast, text retrieval uses discrete tokens and inverted indices for large-scale search. CoRGII’s core idea is to learn a differentiable graph tokenizer that turns graph structures into tokenized representations compatible with inverted-index retrieval, while preserving their structural semantics.
Problem Setup
Given a query graph $G_q$ and corpus graphs ${G_c}$, the goal is to find graphs that contain $G_q$ as a subgraph. A graph encoder (e.g., GNN) generates contextual node embeddings, and a learned soft alignment model provides a reranking score to refine final retrieval results.
The reranking alignment score is:
\[d_{q,c} = \sum_{i,u} [\mathbf{H}_q - \mathbf{P}\mathbf{H}_c]_+[u,i].\]Core Components
Here, we discuss the core components of our retrieval pipeline. We summarize the components in the figure below.
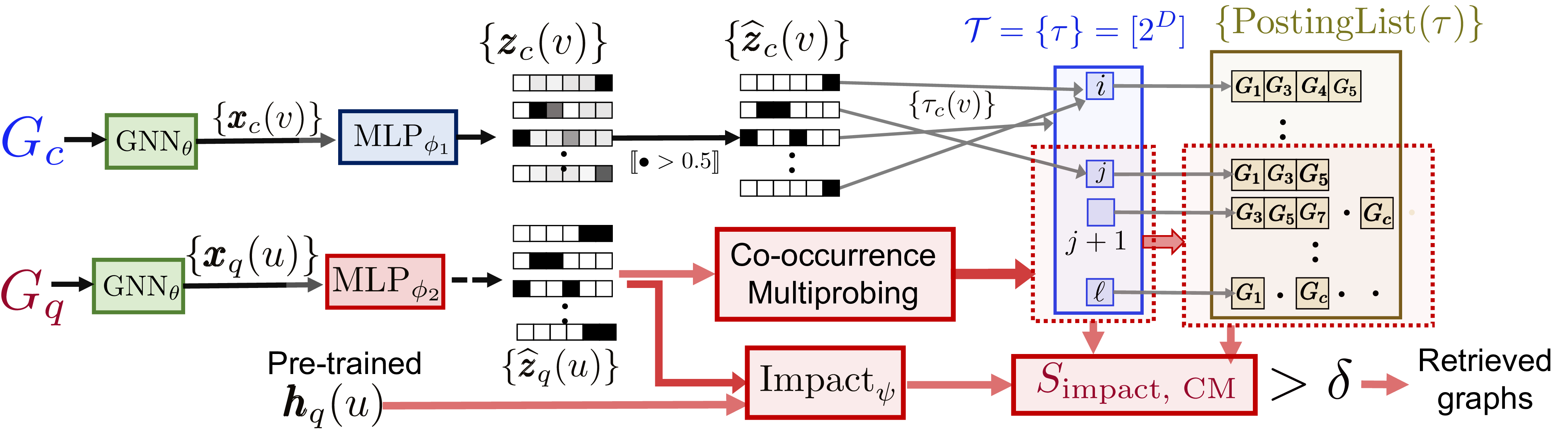
1. Graph Tokenizer
A shared GNN produces contextual node embeddings. Two asymmetric MLP heads (for query and corpus) project these embeddings into a near-binary token space:
\[\mathbf{z}_q(u) = \sigma(\mathrm{MLP}_{\phi_1}(\mathrm{GNN}_\theta(G_q))).\]The asymmetry ensures directional matching—important for subgraph containment. A Chamfer loss aligns query and corpus embeddings:
\[\mathcal{L}_{\text{token}} = \sum_q [\mathrm{Chamfer}(G_q,G_{c_+}) - \mathrm{Chamfer}(G_q,G_{c_-}) + m]_+.\]2. Discretization and Indexing
Each node embedding is thresholded to obtain binary tokens:
\[\hat{\mathbf{z}}(v) = \llbracket \mathbf{z}(v) > 0.5 \rrbracket.\]These tokens form a multiset $\omega(G)$, which defines the inverted index:
\[\mathrm{PL}(\tau) = \{ c : \tau \in \omega(G_c) \}.\]3. Impact Weighting
A lightweight MLP assigns importance scores to each token based on its embedding context:
\[\varphi_\psi(\tau, \mathbf{h}) = \mathrm{MLP}_\psi([\tau; \mathbf{h}]).\]The impact-weighted score combines token importance and token match:
\[S_{\text{impact}}(G_q,G_c) = \sum_{u\in V_q} \varphi_\psi(\hat{\mathbf{z}}_q(u), \mathbf{h}_q(u)), \mathbb{1}[\hat{\mathbf{z}}_q(u)\in\omega(G_c)].\]4. Multi-Probing for Recall
Instead of exact token matches, CoRGII expands token queries using Hamming proximity or co-occurrence statistics. The co-occurrence measure is defined as:
\[\mathrm{sim}(\tau,\tau') = \frac{|\mathrm{PL}(\tau) \cap \mathrm{PL}(\tau')|}{\sum_{\tau_*}|\mathrm{PL}(\tau)\cap\mathrm{PL}(\tau_*)|}.\]This allows the retrieval of semantically related tokens that improve recall without excessive computation.
5. Candidate Selection and Reranking
Graphs retrieved via token overlap are re-ranked using the alignment distance $d_{q,c}$. The shortlisted candidate set is:
\[\mathcal{R}_q(\delta) = \{ G_c : S_{\square(G_q,G_c}) \geq \delta \},\]where \(\square \in \{\text{unif}, \text{impact}, \text{impact+HM}, \text{impact+CM}\}\). Each of the impact score functions (other than vanilla impact) is described below.
\[S_{\text{unif}}(G_q, G_c) = \sum_{u \in V_q} \mathbb{I}\!\left[\hat{\mathbf{z}}_q(u) \in \omega(G_c)\right]\] \[S_{\text{impact+HM}}(G_q, G_c) = \sum_{u \in V_q} \sum_{\tau \in B_r(\hat{\mathbf{z}}_q(u))} \text{Impact}_{\psi}\!\left(\tau, \mathbf{h}_q(u)\right) \mathbb{I}\!\left[\tau \in \omega(G_c)\right]\] \[S_{\text{impact+CM}}(G_c, G_q) = \sum_{u \in V_q} \sum_{\tau \in \mathcal{N}_b(\hat{\mathbf{z}}_q(u))} \text{sim}\!\left(\tau, \hat{\mathbf{z}}_q(u)\right) \text{Impact}_{\psi}\!\left(\tau, \mathbf{h}_q(u)\right) \mathbb{I}\!\left[\tau \in \omega(G_c)\right]\]Note that for simplicity, we overload the method signature of the Impact network and the sim function to accept both tokens and their corresponding discretized vectors. The uniform scheme does not apply any learned weighting. The impact+HM and impact+CM schemes involve training the impact networks with query multi-probing, of type Hamming or co-occurrence. The Hamming multi-probing scheme expands the query within a Hamming ball of radius $r$ bits. The co-occurrence multi-probing scheme expands to the top-$b$ tokens according to the sim values.
Experimental Findings
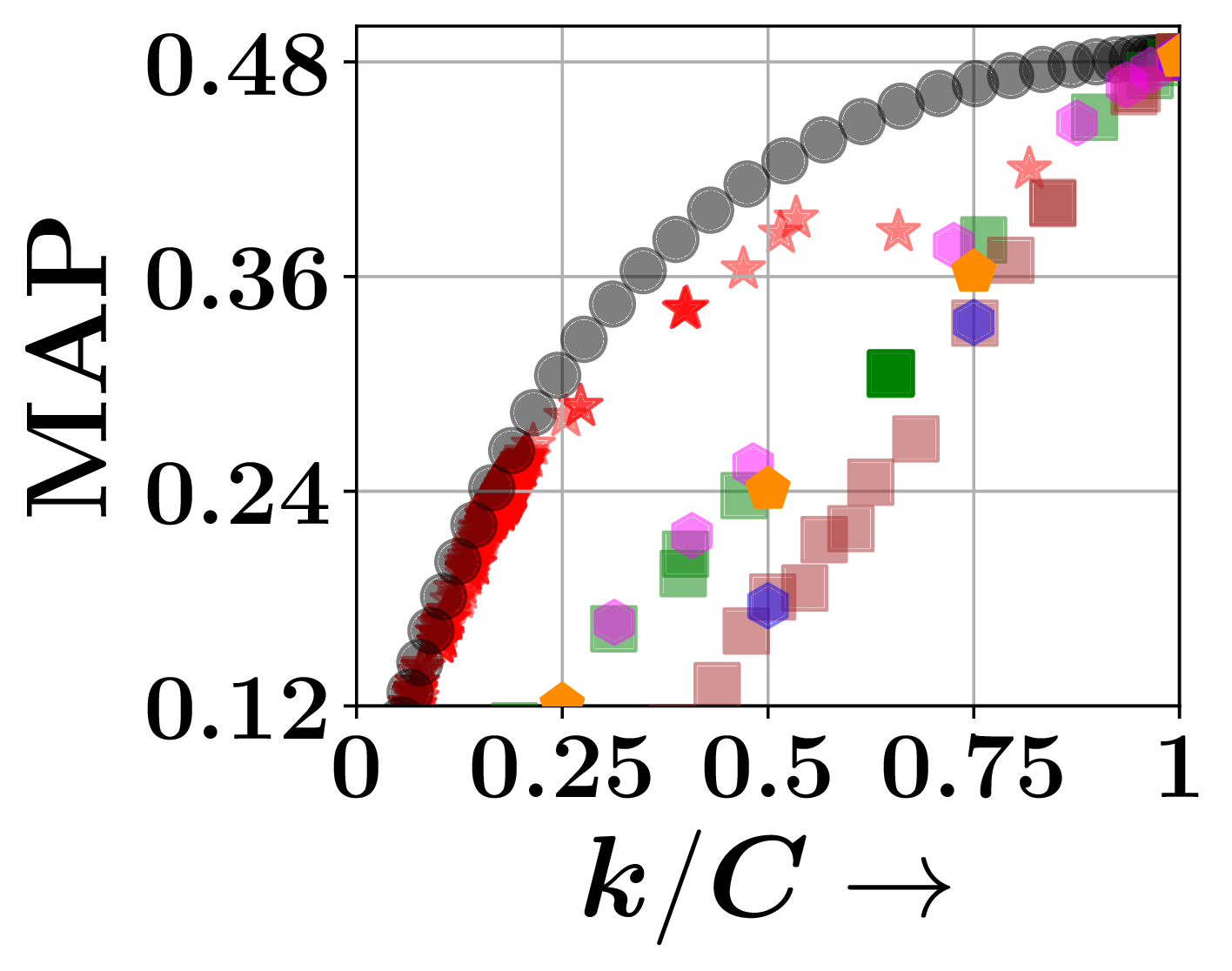
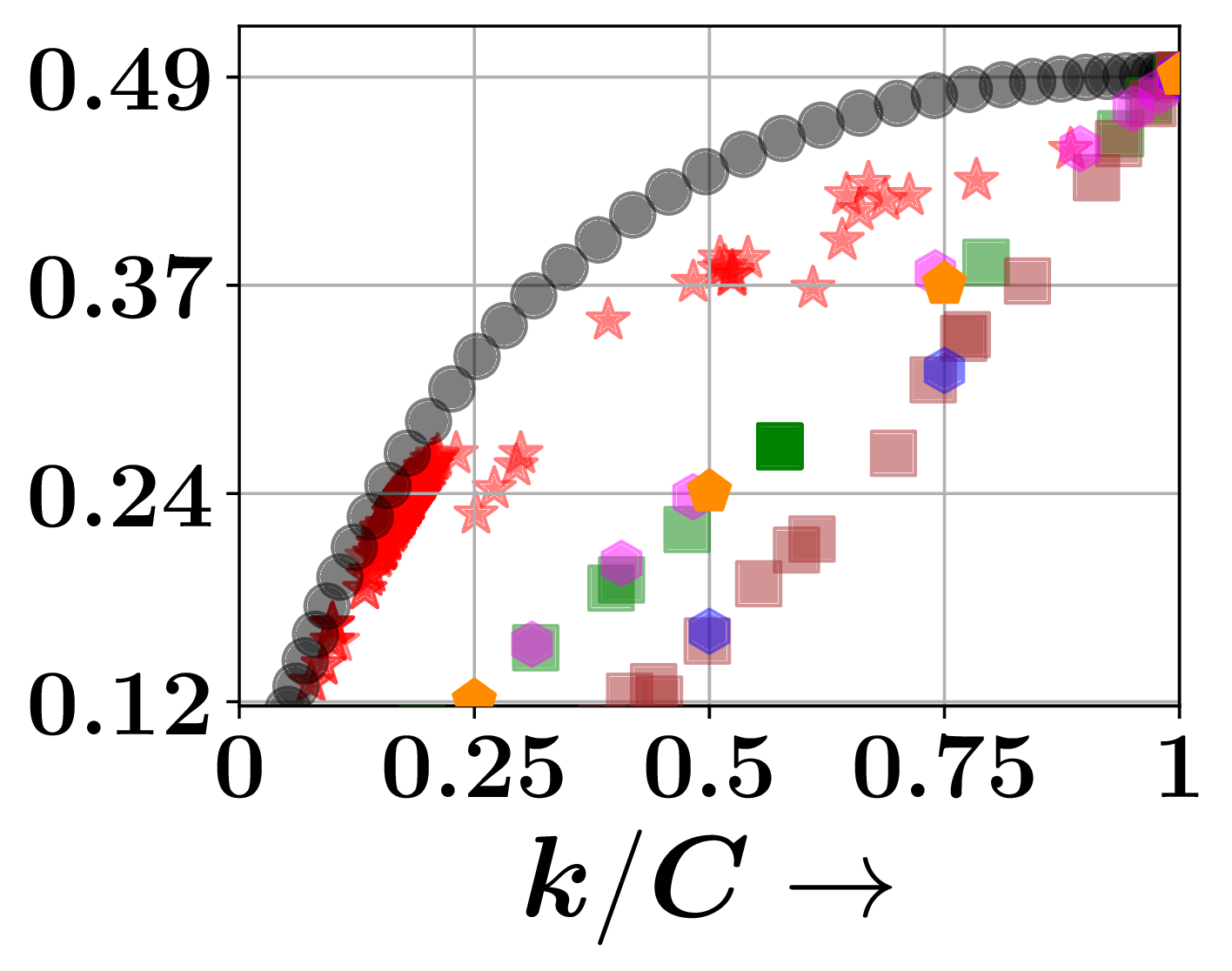
Comparison against baselines. These figures describe retrieval accuracy–efficiency trade-offs on the PTC-FR and PTC-FM datasets. CoRGII comfortably outperforms its competitors.
- Datasets: TU benchmark — PTC-FR, PTC-FM, COX2, and PTC-MR. We sample corpus and query graphs from each of these datasets. There are 100K corpus graphs, and {300, 100, 100} query graphs in the {train, val, test} splits.
- Baselines: FourierHashNet, IVF/DiskANN (single & multi-vector), Random.
- Metric: Mean Average Precision (MAP) vs. retrieval budget ($k/C$).
Key Results:
- CoRGII achieves higher MAP at lower retrieval budgets compared to all baselines.
- Co-occurrence multi-probing yields consistently higher recall than Hamming-based probing.
- Impact weighting improves both precision and stability.
- Asymmetric heads outperform siamese encoders for directional subgraph retrieval.
Conclusion
CoRGII introduces a differentiable tokenization scheme for graphs, enabling efficient inverted-index retrieval without losing semantic structure. Its combination of impact weighting and co-occurrence probing achieves strong accuracy–efficiency trade-offs, making it a practical foundation for large-scale graph search.
Future directions:
- End-to-end learned indexing
- Adaptive token vocabularies
- Temporal or attributed graph extensions
- Integration into retrieval-augmented generation pipelines
Contact
If you have any questions or suggestions, please reach out to Pritish or Indradyumna.