Multi-way Representation Alignment with Geometry-Corrected Procrustes
One assumption present in most representation alignment work is that alignment is to be done in pairs. This is a sensible starting point, but quickly breaks down at scale. For example, if one has $M$ independently trained encoders and wants them to be mutually interoperable, pairwise alignment requires fitting $O(M^2)$ alignment maps. Introducing the $M + 1$th model requires re-fitting the existing $M$ models for the sake of the new one. Additionally, composed translations — going from model A to C by way of B — are not guaranteed to be consistent with the direct A-to-C map, even when each individual pairwise map is good. This may happen due to the error incurred when going to C via B.
So our paper asks: what if we instead aligned everything into a single shared universe? This would entail one map per model, and all cross-model translations would be obtained by composing through that reference. The complexity then drops to $O(M)$, adding a new model costs exactly one map, and translations are consistent by construction. We set out with these goals in mind.
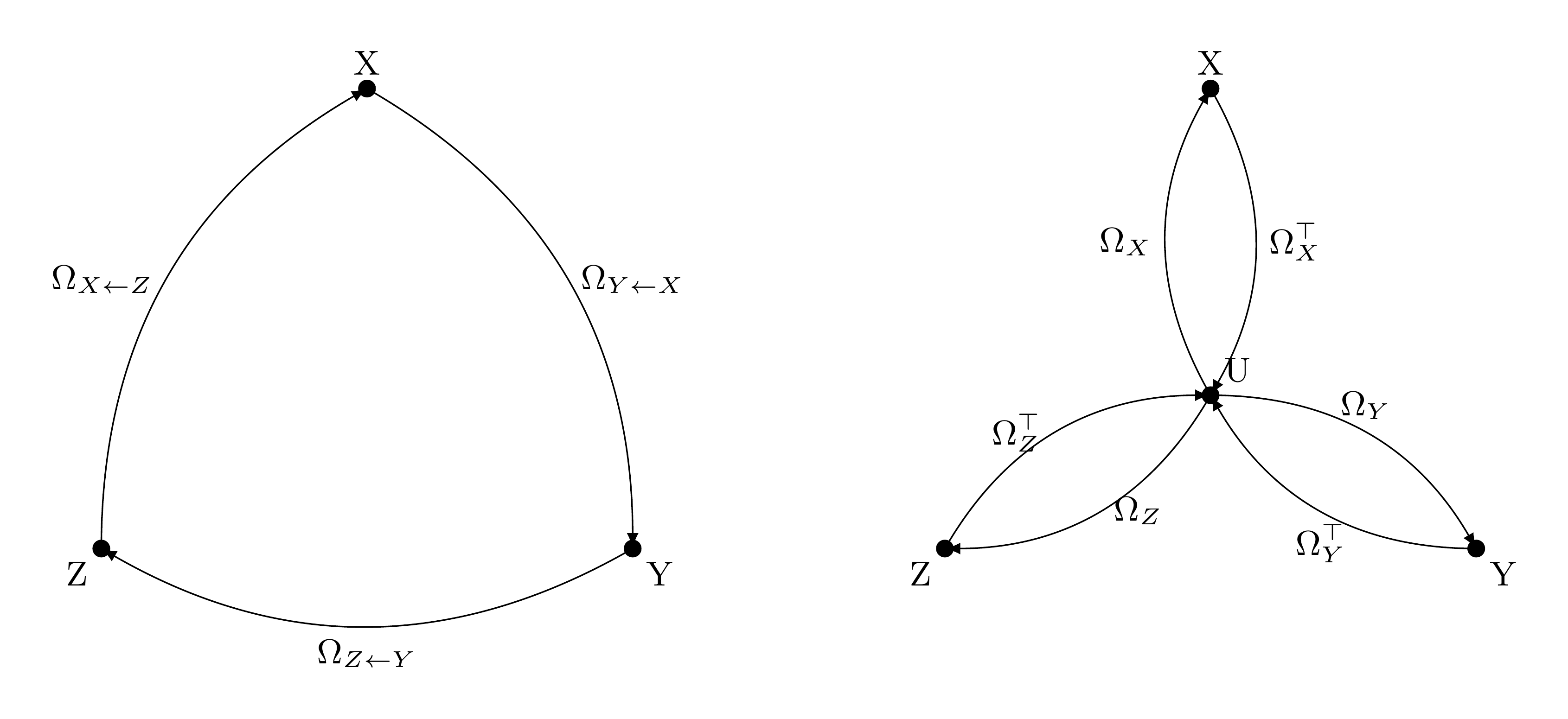
The geometric tension at the core of alignment
One way to build a shared universe is via Generalized Procrustes Analysis (GPA): this algorithm finds orthogonal maps ${\Omega_m}$ and a consensus centroid $U$ that jointly minimize the total dispersion of all models around the shared reference. Because orthogonal maps are isometries — they preserve distances and angles — the internal geometry of each model survives intact in the universe. This is essential for tasks like model stitching, where a linear probe trained on one model’s features needs to transfer to another.
The key issue is that isometry is too rigid for retrieval. In zero-shot cross-modal or cross-lingual retrieval, matched items need to be close in the shared space, and that often requires reshaping the feature spaces — suppressing modality-specific noise, or rotating toward a common alignment. Orthogonal maps don’t have that freedom. Methods such as Generalized Canonical Correlation Analysis (GCCA), which relax the orthogonality constraint and maximize cross-view agreement, consistently outperform GPA on retrieval benchmarks as a result.
So we face a choice: geometric fidelity (GPA) or retrieval performance (GCCA). GCCA being a shared-basis method rather than a universe method, doesn’t give us a reusable coordinate system that we can extend incrementally.
GCPA: a correction on top of the scaffold
We develop Geometry-Corrected Procrustes Alignment (GCPA) for this purpose. We start with GPA to obtain a geometrically sound orthogonal universe, then apply a lightweight shared correction to reduce the residual directional mismatch — without throwing away the universe structure.
The correction is motivated by a simple observation: once all models are mapped into the GPA universe, one can compute a consensus direction for each sample by averaging the unit-normalized directions across all $M$ models. Moving each model’s representation toward that consensus strictly increases pairwise cosine similarity across models. Thus, a small shared MLP $T_\theta$, trained to nudge universe embeddings toward their per-sample consensus while staying close to the original GPA direction, does exactly this. The trust penalty in the objective prevents the correction from straying too far from the Procrustes-imposed geometry.
Because $T_\theta$ is shared across all models and operates on universe coordinates, it corrects the universe itself rather than individual models — and the composable structure is preserved.
But does it actually work?
The universe heals weak links. One experiment trains two models on severely corrupted data (85% of images replaced with edge maps), creating a pair with almost no direct correspondence. Direct pairwise alignment fails on this pair. Placing them in a universe alongside standard RGB-trained models — and progressively adding more anchor models — monotonically recovers the alignment between the fragile pair. The universe triangulates the relationship through the consensus of the anchors.
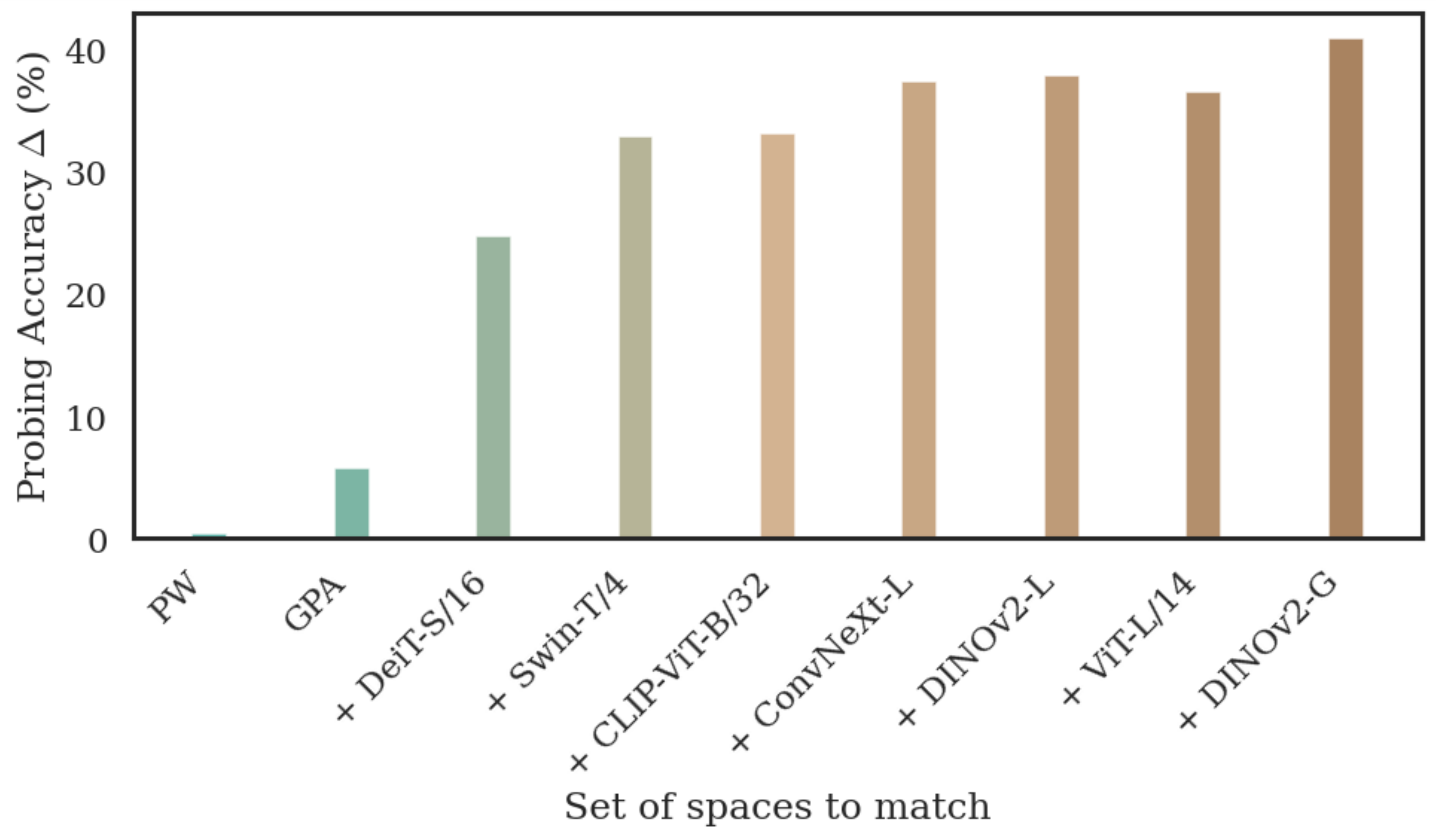
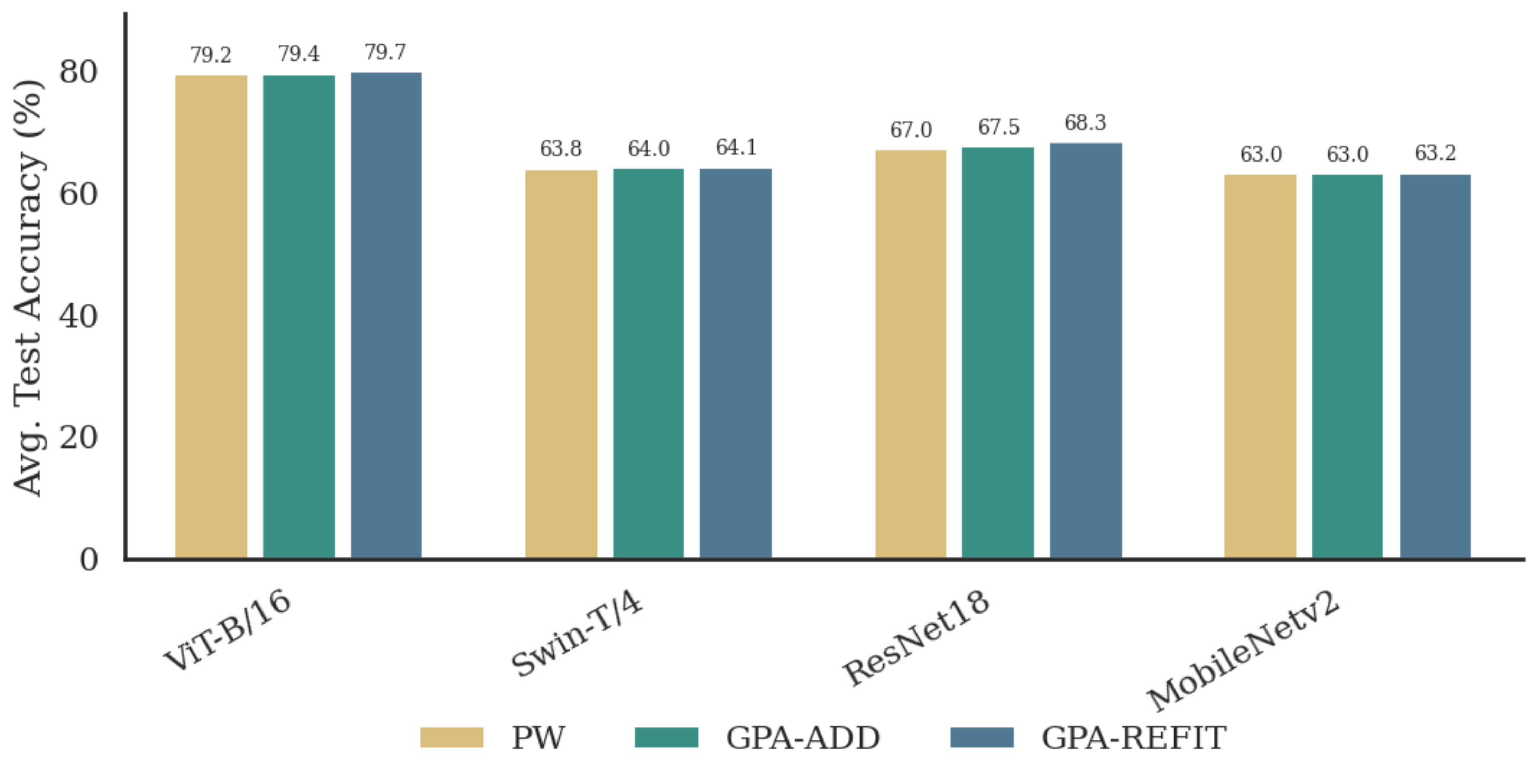
Adding models is cheap. On CIFAR-100, fitting a new model into a fixed existing universe (GPA-ADD — one new map, no refitting) matches or outperforms the much more expensive approach of refitting all pairwise maps from scratch. The shared coordinate system absorbs new models gracefully.
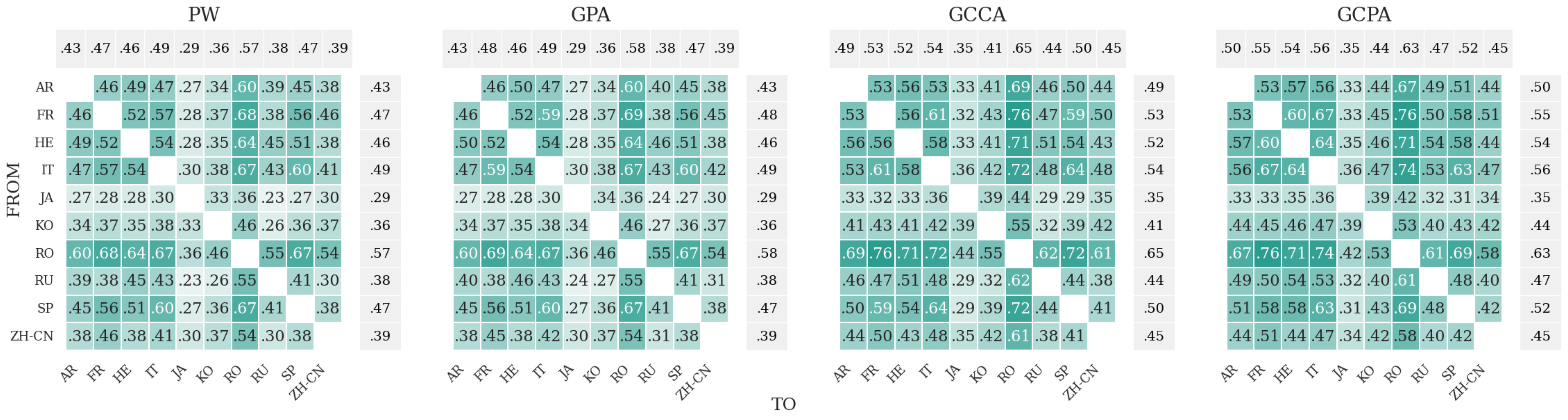
Cross-lingual retrieval. On TED-MULTI with 10 languages, each embedded by a dedicated monolingual encoder, direct comparison in the original spaces yields near-zero retrieval accuracy. GCPA achieves the best rank-1 retrieval across all language pair combinations, outperforming both GCCA and GPA, and does so while also improving the worst-case pair.
We then perform a stress test that corrupts 75% of training correspondences before fitting alignment. GCCA collapses badly under this corruption — it relies heavily on clean paired signals to find its shared basis. GCPA degrades far more gracefully, staying close to its unshuffled performance.
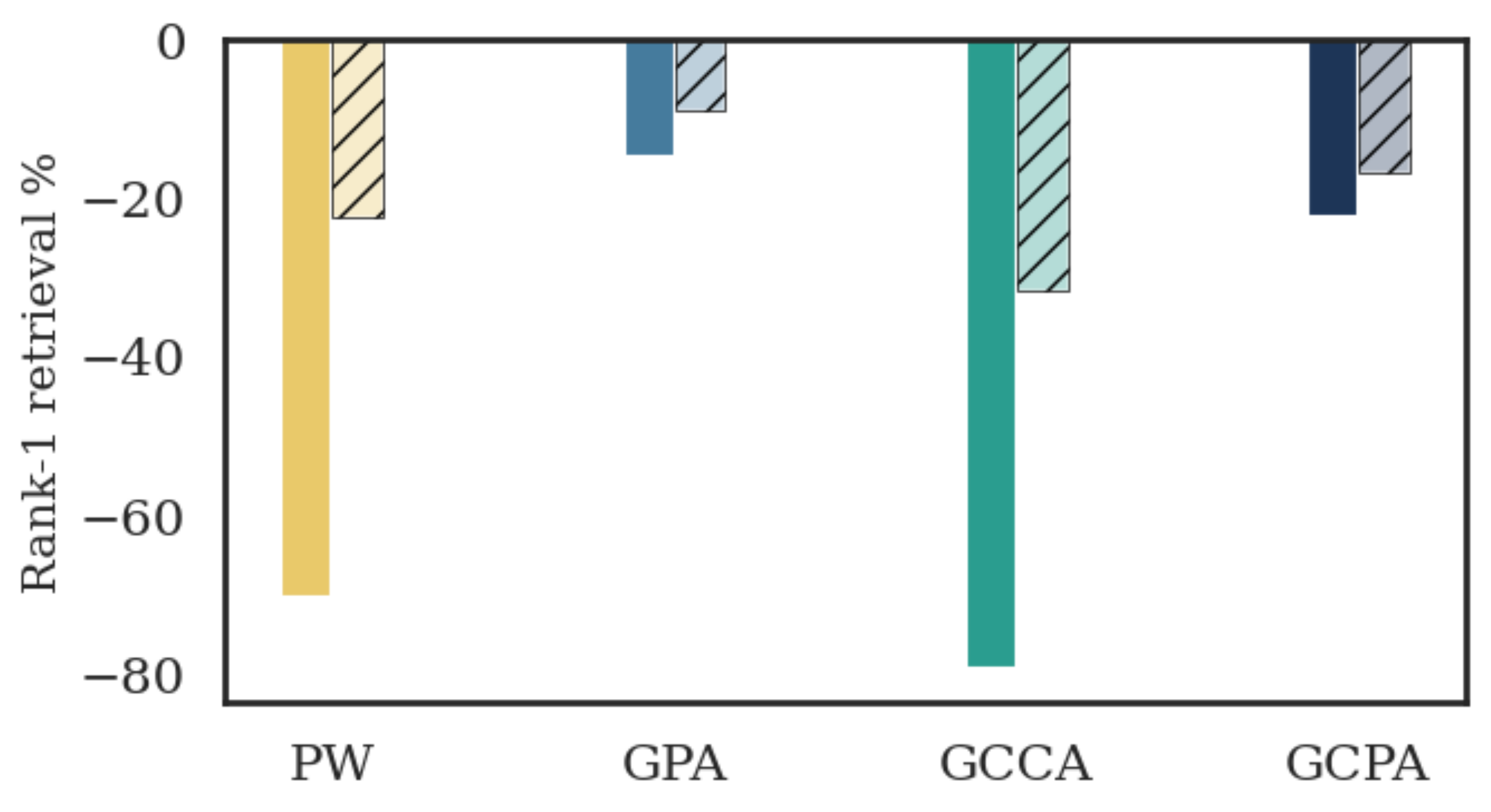
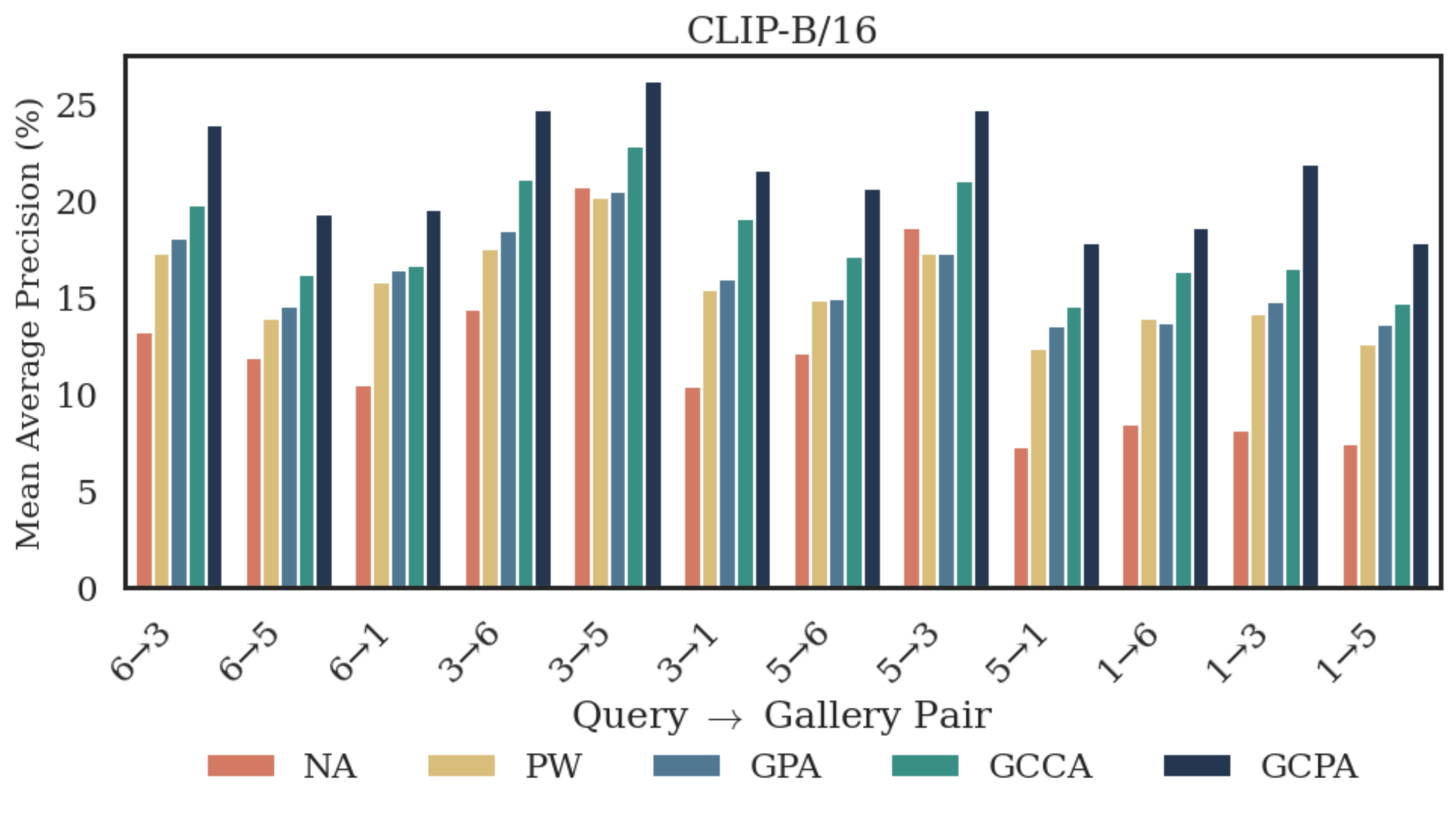
Cross-camera person re-identification. Without alignment, independently trained camera-specific encoders fail to generalize across views. GCPA achieves the highest mean average precision on the MARKET-1501 dataset across all camera pairs, with the largest improvements in the harder transitions where GCCA also struggles.
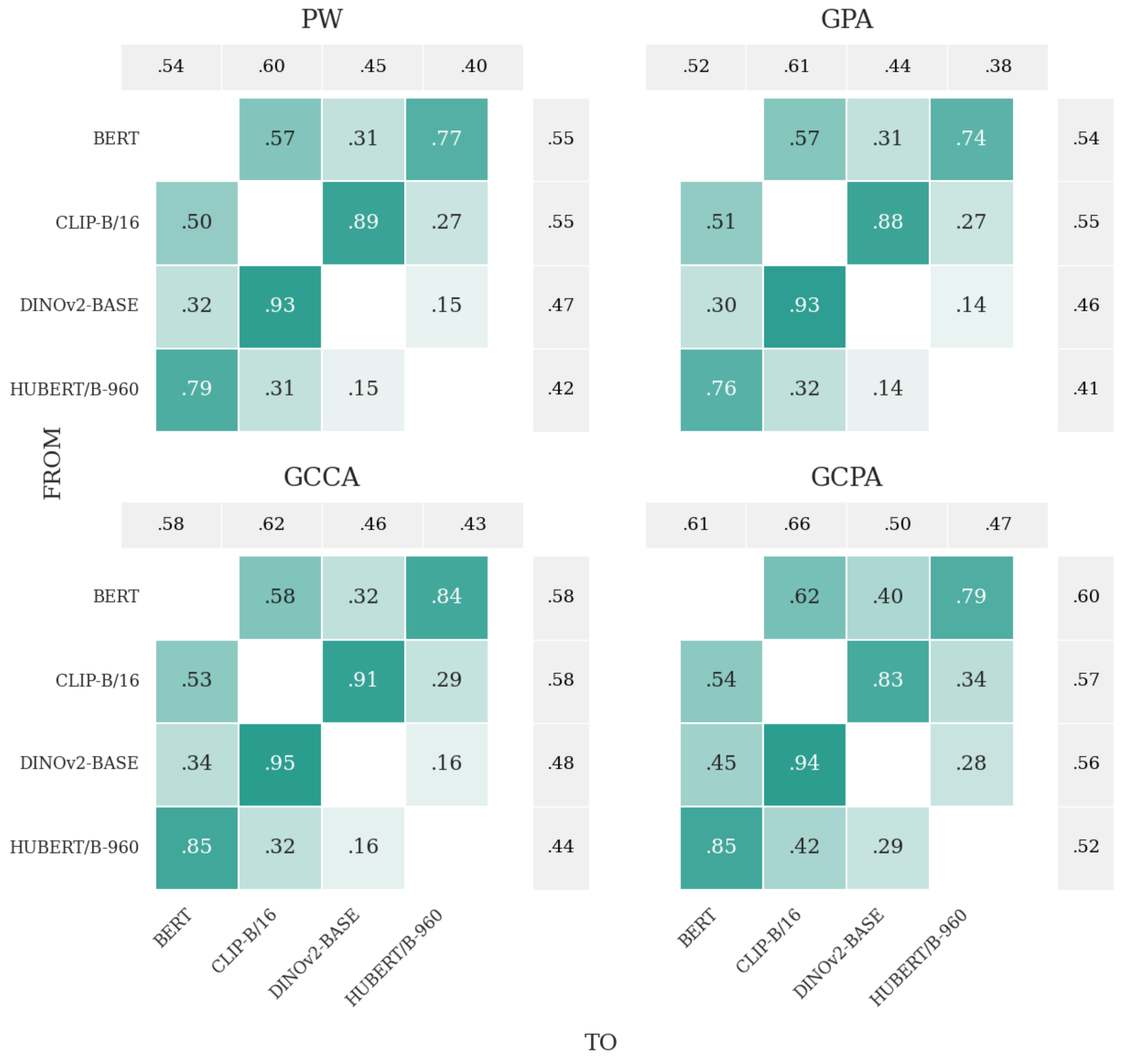
Multimodal alignment. Audio-visual alignment is where the gap between GPA and GCPA is most stark. HuBERT→DINOv2 retrieval under GPA is only 14–15% — audio and vision features sit in very different regions of the GPA universe. GCPA’s consensus correction pulls audio representations toward the shared reference, roughly doubling retrieval accuracy on those pairs.
What this means for the broader representation alignment space
The Platonic Representation Hypothesis has been driving a lot of interest in whether independently trained models can be made interoperable without retraining. Most of the resulting alignment work is pairwise, which limits practical applicability: the cost grows quadratically, consistency is not guaranteed, and there is no natural way to maintain a shared reference across a growing collection of models.
GCPA addresses these limits directly. The universe formulation is what makes it practical — linear cost, incremental extension, cycle consistency, all by design. The geometrical correction is what makes it competitive, closing the gap with agreement-maximizing methods like GCCA without giving up the reusable structure.
One limitation of our method is that the correction relies on a meaningful multi-model consensus. In settings where the participating spaces are too weakly related (very few anchor models, or heavily corrupted training correspondences), the consensus itself can be unreliable and GPA becomes the safer choice. The paper characterizes this failure mode clearly and provides a guideline on when to use each method.
Contact
If you have any questions, feel free to reach out to Akshit, Pritish, or any of the authors.